 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Provably Learn to Internalize Chain-of-Thought
May 27, 2026Chain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states, but its theoretical foundations remain poorly understood. We give the first theoretical analysis of ICoT, proving that an $L$-layer transformer trained under our proposed Log-ICoT curriculum learns $k$-parity with $\mathsf{poly}(n)$ samples and $L = \log_2 k$ training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in $k$ to logarithmic. Experiments on multi-layer transformers confirm the theory and visualize how reasoning is progressively absorbed into deeper layers.
Multi-Objective Learning for Diffusion Models: A Statistical Theory under Semi-Supervised Learning
May 24, 2026Diffusion models are increasingly used as powerful conditional generators, yet real deployments often involve multiple target distributions arising from different tasks, e.g., diverse prompt domains in text-to-image generation, or multiple environments in robotics with diffusion policies. This naturally leads to a multi-objective learning (MOL) problem. A key challenge is that achieving good Pareto trade-offs can require a generalist model class with substantially larger capacity than what suffices for solving any individual task, thereby increasing statistical cost since sample complexity typically scales with the model complexity. To reconcile this, we develop a principled MOL framework for diffusion models with limited data: a semi-supervised regime where paired (labeled) samples are scarce, but (unlabeled) condition data are abundant. We propose a two-stage training procedure that first fits lightweight specialist models from limited paired data, and then distills them into a generalist model by generating pseudo-samples. We establish generalization bounds showing that the required number of paired samples only depends on the complexity of the specialist model classes. We further extend the theory to diffusion policies for sequential decision making to account for distribution shift in on-policy rollouts. Extensive experiments on robotic control and image restoration tasks are conducted to verify our theoretical results.
CopT: Contrastive On-Policy Thinking with Continuous Spaces for General and Agentic Reasoning
May 19, 2026Chain-of-thought (CoT) is a standard approach for eliciting reasoning capabilities from large language models (LLMs). However, the common CoT paradigm treats thinking as a prerequisite for answering, which can delay access to plausible answers and incur unnecessary token costs even when the model is able to identify an answer before extended thinking, a behavior known as performative reasoning. In this paper, we introduce CopT, a reformulated reasoning pipeline that reverses the usual order of thinking and answering. Instead of thinking before answering, CopT first elicits a draft answer and then invokes subsequent on-policy thinking conditioned on its own draft answer for reflection and correction. To assess whether the draft answer should be trusted, CopT recasts continuous embeddings as inference-time contrastive verifiers. Specifically, it contrasts the model's support for the same generated tokens under discrete-token inputs and continuous-embedding inputs, yielding a sequence-level reverse KL estimator for answer reliability. Our analysis shows that under certain assumptions, the expected estimate equals the mutual information between the unresolved latent state and the emitted answer token, explaining why it captures answer-relevant uncertainty rather than arbitrary uncertainty in the latent state. When the answer is deemed insufficiently reliable, CopT performs further on-policy thinking, where a second KL estimator dynamically controls draft-answer visibility, preserving useful partial information while reducing the risk of being misled by unreliable content. Across mathematics, coding, and agentic reasoning tasks, CopT improves peak accuracy by up to 23% and reduces token usage by up to 57% at comparable or higher accuracy, without any additional training. The code is available at https://github.com/sdc17/CopT.
Breaking the Reversal Curse in Autoregressive Language Models via Identity Bridge
Feb 02, 2026Autoregressive large language models (LLMs) have achieved remarkable success in many complex tasks, yet they can still fail in very simple logical reasoning such as the "reversal curse" -- when trained on forward knowledge data of the form "$A \rightarrow B$" (e.g., Alice's husband is Bob), the model is unable to deduce the reversal knowledge "$B \leftarrow A$" (e.g., Bob's wife is Alice) during test. Extensive prior research suggests that this failure is an inherent, fundamental limit of autoregressive causal LLMs, indicating that these models tend to memorize factual-level knowledge rather than capture higher-level rules. In this paper, we challenge this view by showing that this seemingly fundamental limit can be mitigated by slightly tweaking the training data with a simple regularization data recipe called the Identity Bridge of the form "$A \to A$" (e.g., The name of Alice is Alice). Theoretically, we prove that under this recipe, even a one-layer transformer can break the reversal curse by analyzing the implicit bias of gradient descent. Empirically, we show that a 1B pretrained language model finetuned with the proposed data recipe achieves a 40% success rate on reversal tasks, in stark contrast to a near-zero success rate when trained solely on forward-knowledge data. Our work provides a novel theoretical foundation for the reversal curse and offers a principled, low-cost path to encouraging LLMs to learn higher-level rules from data.
GSM-Agent: Understanding Agentic Reasoning Using Controllable Environments
Sep 26, 2025
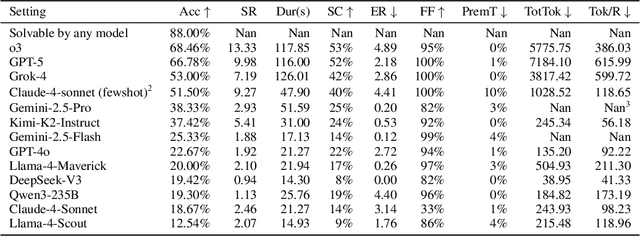


As LLMs are increasingly deployed as agents, agentic reasoning - the ability to combine tool use, especially search, and reasoning - becomes a critical skill. However, it is hard to disentangle agentic reasoning when evaluated in complex environments and tasks. Current agent benchmarks often mix agentic reasoning with challenging math reasoning, expert-level knowledge, and other advanced capabilities. To fill this gap, we build a novel benchmark, GSM-Agent, where an LLM agent is required to solve grade-school-level reasoning problems, but is only presented with the question in the prompt without the premises that contain the necessary information to solve the task, and needs to proactively collect that information using tools. Although the original tasks are grade-school math problems, we observe that even frontier models like GPT-5 only achieve 67% accuracy. To understand and analyze the agentic reasoning patterns, we propose the concept of agentic reasoning graph: cluster the environment's document embeddings into nodes, and map each tool call to its nearest node to build a reasoning path. Surprisingly, we identify that the ability to revisit a previously visited node, widely taken as a crucial pattern in static reasoning, is often missing for agentic reasoning for many models. Based on the insight, we propose a tool-augmented test-time scaling method to improve LLM's agentic reasoning performance by adding tools to encourage models to revisit. We expect our benchmark and the agentic reasoning framework to aid future studies of understanding and pushing the boundaries of agentic reasoning.
Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers
Jun 12, 2025Large language models (LLMs) can acquire new knowledge through fine-tuning, but this process exhibits a puzzling duality: models can generalize remarkably from new facts, yet are also prone to hallucinating incorrect information. However, the reasons for this phenomenon remain poorly understood. In this work, we argue that both behaviors stem from a single mechanism known as out-of-context reasoning (OCR): the ability to deduce implications by associating concepts, even those without a causal link. Our experiments across five prominent LLMs confirm that OCR indeed drives both generalization and hallucination, depending on whether the associated concepts are causally related. To build a rigorous theoretical understanding of this phenomenon, we then formalize OCR as a synthetic factual recall task. We empirically show that a one-layer single-head attention-only transformer with factorized output and value matrices can learn to solve this task, while a model with combined weights cannot, highlighting the crucial role of matrix factorization. Our theoretical analysis shows that the OCR capability can be attributed to the implicit bias of gradient descent, which favors solutions that minimize the nuclear norm of the combined output-value matrix. This mathematical structure explains why the model learns to associate facts and implications with high sample efficiency, regardless of whether the correlation is causal or merely spurious. Ultimately, our work provides a theoretical foundation for understanding the OCR phenomenon, offering a new lens for analyzing and mitigating undesirable behaviors from knowledge injection.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025



As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
May 18, 2025Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with $D$ steps of continuous CoTs can solve the directed graph reachability problem, where $D$ is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires $O(n^2)$ decoding steps where $n$ is the number of vertices ($D<n$). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
How Do LLMs Perform Two-Hop Reasoning in Context?
Feb 19, 2025



"Socrates is human. All humans are mortal. Therefore, Socrates is mortal." This classical example demonstrates two-hop reasoning, where a conclusion logically follows from two connected premises. While transformer-based Large Language Models (LLMs) can make two-hop reasoning, they tend to collapse to random guessing when faced with distracting premises. To understand the underlying mechanism, we train a three-layer transformer on synthetic two-hop reasoning tasks. The training dynamics show two stages: a slow learning phase, where the 3-layer transformer performs random guessing like LLMs, followed by an abrupt phase transitions, where the 3-layer transformer suddenly reaches $100%$ accuracy. Through reverse engineering, we explain the inner mechanisms for how models learn to randomly guess between distractions initially, and how they learn to ignore distractions eventually. We further propose a three-parameter model that supports the causal claims for the mechanisms to the training dynamics of the transformer. Finally, experiments on LLMs suggest that the discovered mechanisms generalize across scales. Our methodologies provide new perspectives for scientific understandings of LLMs and our findings provide new insights into how reasoning emerges during training.
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Feb 05, 2025



Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.